That project sounds very cool and thanks for sharing!
And, yes, a lot of the nuance as to how things will perform will come down to the linear solver. With respect to IPOPT vs Optizelle, one of the core differences is what linear system gets solved. As a disclaimer, I do not work on the IPOPT code, so there may be some errors in what I’m about to write. Wächter and Biegler describe their algorithm in the paper On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. The linear system that they solve can be seen in equation 13:
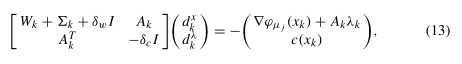
To solve that system, they hook into a variety of HSL routines, which are helpfully described by HSL themselves here.
Now, there are a number of differences and similarities between Optizelle and IPOPT. The general framework for getting the inequalities into the Hessian is similar. Using their notation, the W + Sigma in the above equation is mostly the same. However, Optizelle does not solve the larger system above. Instead, it really comes down to solving, in the above notation, A'*A. Technically, we’re solving a larger augmented system, but it really comes down to that linear algebra solve. Now, the nice thing about that solve rather than the larger system that IPOPT uses is that we get to be more creative on how solve that system. For example, if A represents a PDE, we can then precondition the linear system with a piece of code that does a PDE solve using something like a Runge-Kutta method rather than use a factorization.
That said, it’s not quite as simple as just solving this other system. In order to get to this smaller system to solve, we solve what’s called an augmented system, which is a linear system of the form
[I A]
[A' 0]
To get to this system, we have to employ what is called a composite step SQP method, which breaks apart the step into one that moves toward feasiblity and one that moves toward optimality. This has its own set of difficulties, but it means that the steps that Optizelle and IPOPT take are fundamentally different. And, to be clear, there are lots of other differences from globalization to barrier parameters, but these are the larger differences with respect to linear solvers, which you’ve mentioned. As a brief aside, NITRO also uses a composite step method, but it handles the inequalities and their reduction somewhat differently.
OK, outside of this general academic curiosity, how does the the robustness compare? With no inequalities, it’s probably a wash. With inequalities, IPOPT is probably more robust. This is something that I’m sensitive to and have largely resolved in the new algorithm. There’s a number of reasons as to why. Candidly, the IPOPT algorithm is good and their team has done a fantastic job of refining the algorithm. Depending on the kind of problem, Optizelle has some trouble with repeating running itself into the boundary. That took me some time to understand why and, with the new algorithm, I don’t worry about it ever. At some point in time, I hope to write a good comparison article on why this happens and how it was resolved.
Hopefully that helps a bit and I hope I’m not being too coy. Thanks for the feedback. That helps, really. I’ll try to answer any other questions as best I can.
 but I think I get the gist… Maybe I can explain a little bit about my thoughts from a user’s perspective.
but I think I get the gist… Maybe I can explain a little bit about my thoughts from a user’s perspective.